This article was co-written by applied research scientists Vipul Raheja and Dhruv Kumar.
When you read a piece of high-quality writing, chances are the text you’re seeing is not the first version the author wrote. Editing helps writers refine their thinking, structure their ideas more clearly, and express their voice and style. The editing process is often run iteratively over multiple drafts because the chance for improvements can become apparent after other edits are made. For instance, fixing a grammar mistake may then reveal that the sentence could also be revised to improve clarity. With each round of revisions they make, the author produces a stronger piece of writing.
At ACL 2022, we shared our work on IteraTeR, where we trained models to revise iteratively using a dataset of text annotated with edit intents such as “coherence” or “fluency.” Now, we’re sharing an update on that work, a notable improvement on the state of the art, which we call DELIteraTeR: A Delineate-Edit-Iterate approach to Text Revision¹. DELIteraTeR builds on our previous work by augmenting the IteraTeR corpus with more task-specific data and enabling models to mark editable spans within each input rather than considering only the input as a whole.

An example from our dataset showing spans of text that are annotated with edit intents.
What we did
In our research, we aimed to extend our earlier work on the Iterative Text Revision task by adding more granularity and context.
Like IteraTeR, DELIteraTeR models this task with a two-step approach. First, for each input text, we classify the edits needed and annotate the data with the predicted edit intent. Then, we make text revisions based on these annotations.
DELIteraTeR, however, annotates the text in a more fine-grained way than IteraTeR. The original IteraTeR model simply predicted an edit intent for the entire input text and attached that annotation to the beginning of the text. Now, with DELIteraTeR, we detect the exact span within the text that needs editing and annotate just that fragment. This gives DELIteraTeR more context when making revisions and also allows it to make multiple edits within the input text. To make this more precise annotation possible, we augmented the existing IteraTeR dataset, and we built a new pipeline that incorporated the identification of editable spans.
Dataset augmentation
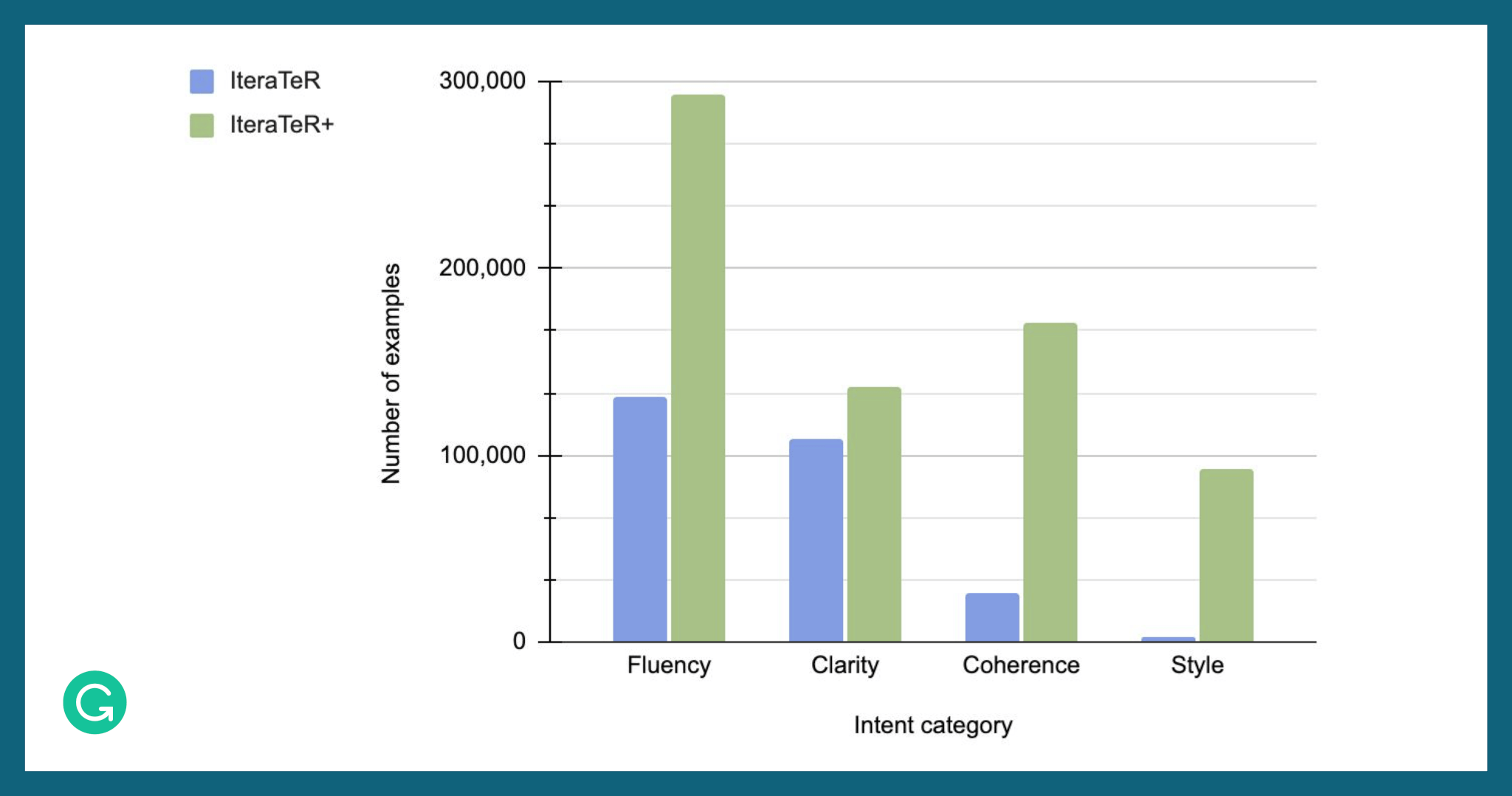
For our span-detection models, we augmented IteraTeR’s dataset with new task-specific data and called the new dataset IteraTeR+. This augmentation was necessary because the original dataset contained noisy revisions that degraded the effectiveness of our models.
To create IteraTeR+, we incorporated datasets from many other text editing tasks. The taxonomy defined in IteraTeR was general and powerful enough that we could use it to categorize the data from those tasks. For instance, we could include datasets from previous work on grammatical error correction as FLUENCY edits and datasets from work on text simplification as CLARITY edits.
With the inclusion of these task-specific datasets, IteraTeR+ contains more than twice as many edit examples as the previous IteraTeR dataset. For the COHERENCE and STYLE intents (the least-represented edit intents in the original IteraTeR dataset), we increased the number of examples by 5X and 30X, respectively.
Intent span detection and revision
After constructing the IteraTeR+ dataset, we trained a model to perform token-level prediction of edit intent, i.e., detecting the exact span to edit. Given a plain-text input, the model would assign each token a label, either one of the edit intents or “no edit needed.” The text would then be annotated with these labels by enclosing the spans to be edited within intent tags.
Following the approach used on IteraTeR, our next step was to fine-tune a powerful Transformer-based PEGASUS model to generate the edited text.
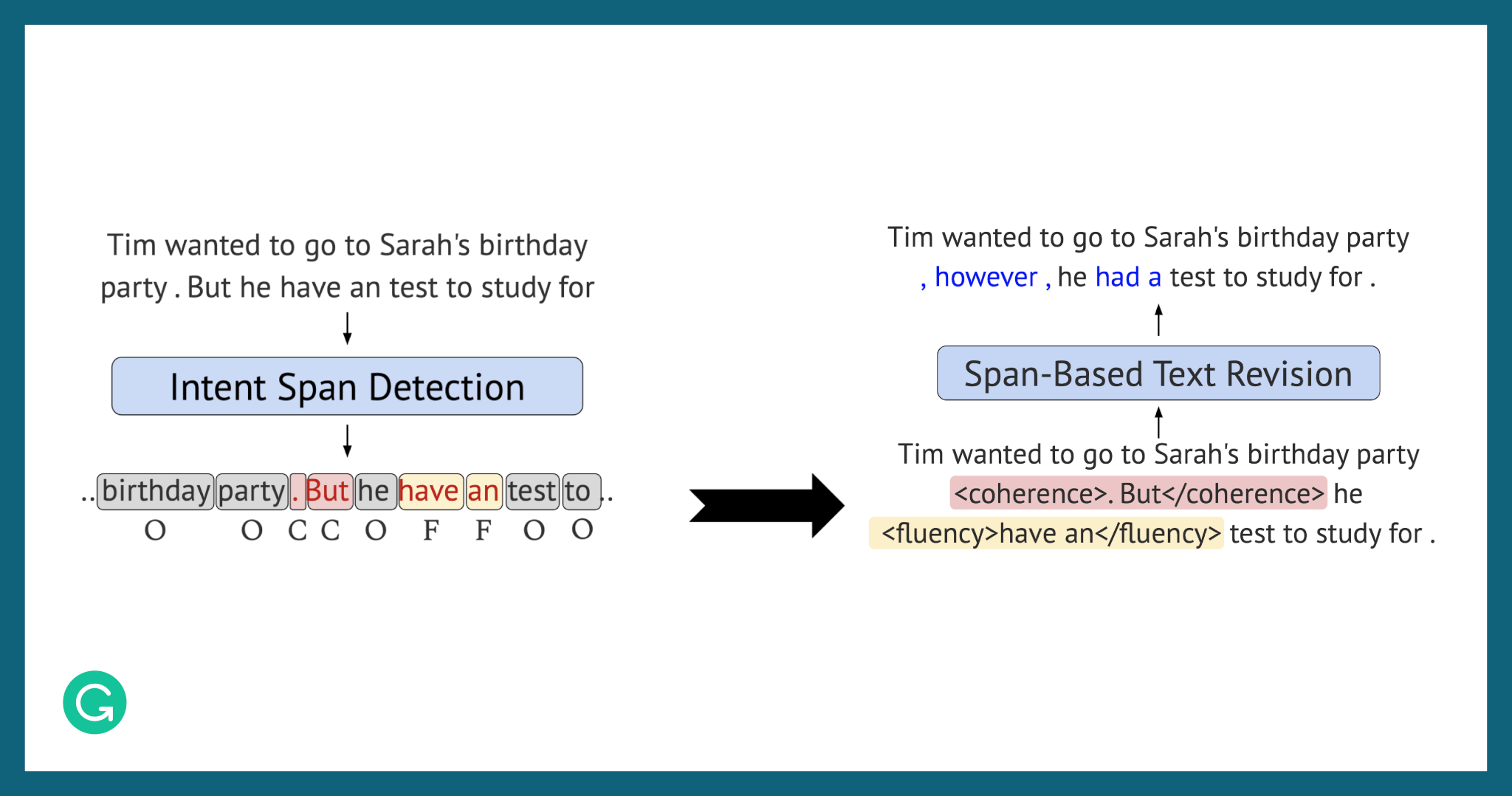
The DELIteraTeR pipeline. You may notice that the example, after one level of revision, is not yet entirely grammatically correct.
What we found
DELIteraTeR consistently outperformed our previous work on Iterative Text Revision. On all test sets, the span-based DELIteraTeR models outperformed IteraTeR models.
DELIteraTeR also outperformed human editors when scored by human evaluators. This is a significant improvement over the performance of IteraTeR, where the revisions underperformed human editors.
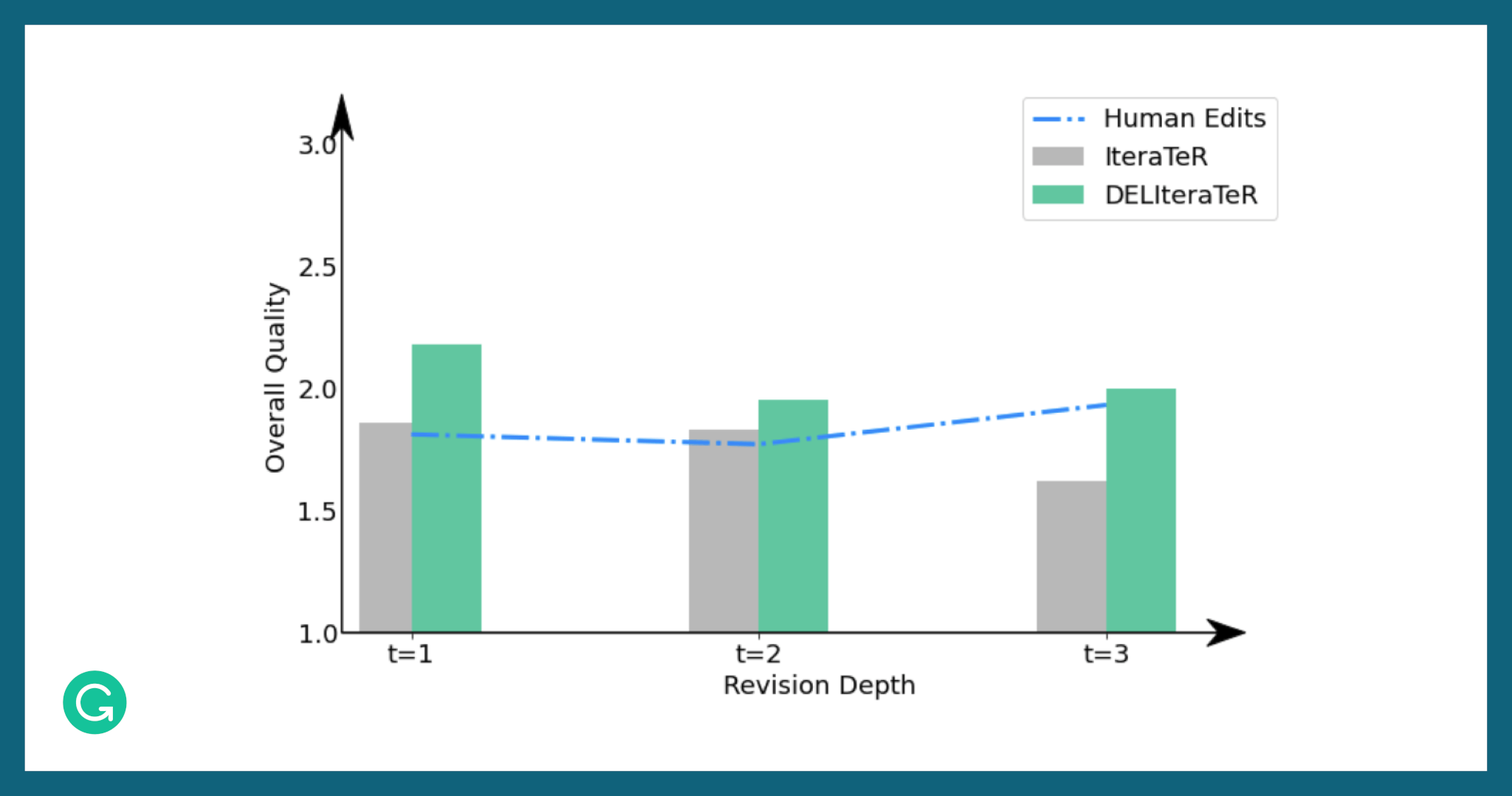
Comparing the quality score for human editors, the top IteraTeR model, and the top DELIteraTeR model, at various revision depths.
Additional explorations
We also explored some interesting related questions using the DELIteraTeR model and datasets.
Dataset
We found that training on the IteraTeR+ dataset considerably influenced the model’s success. An ablation study on different portions of the dataset found that training DELIteraTeR on just the original IteraTeR dataset or one of the task-specific datasets was not as successful as training on the full dataset.
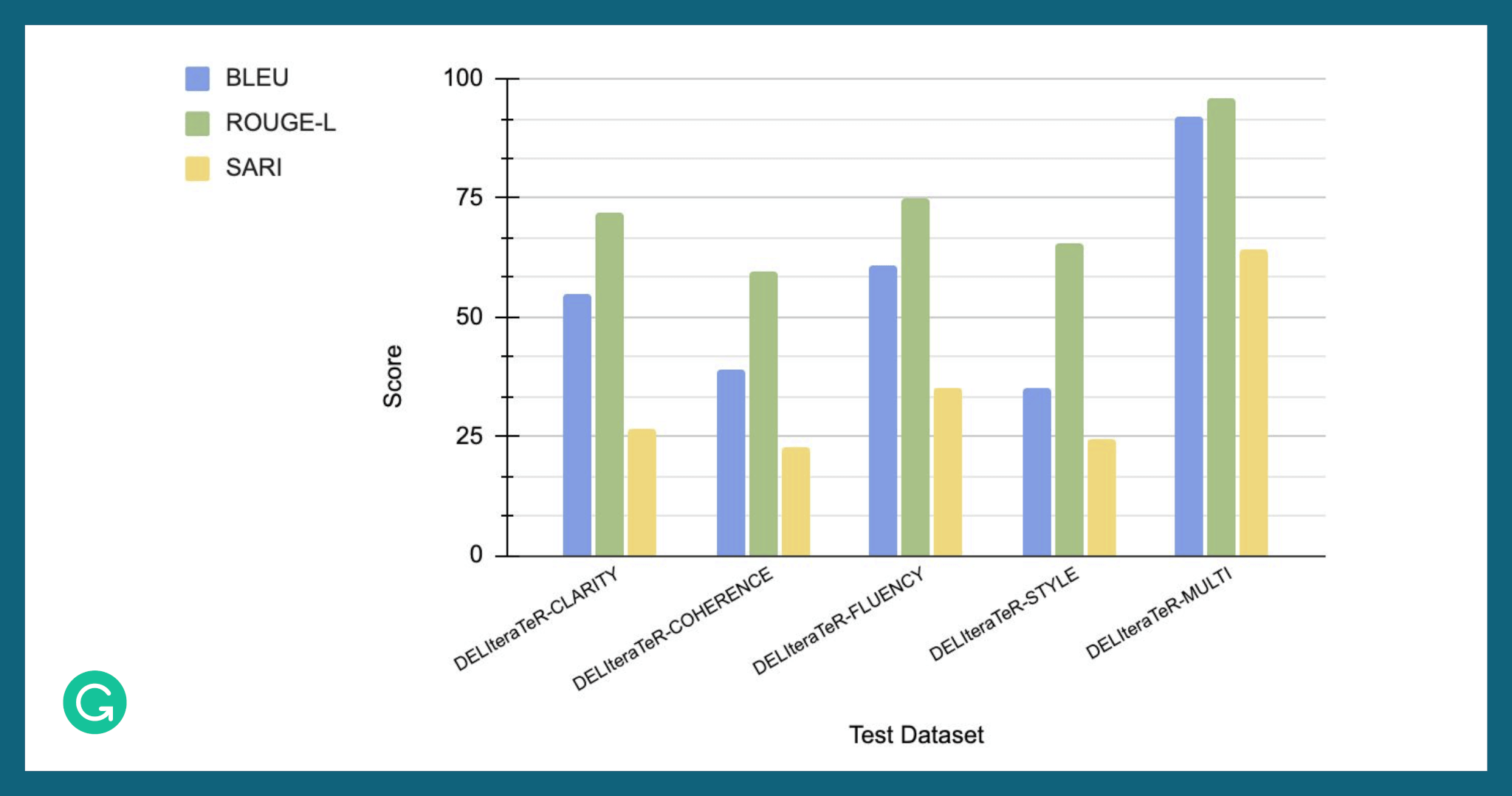
Training a model on the full Iterater+ dataset (DELIteraTeR-MULTI) led to increased performance over models trained on just task-specific data.
While models trained on the task-specific datasets performed well on their corresponding test sets, unsurprisingly, their revision quality dropped significantly when tested on the full IteraTeR-TEST set. Similarly, a model trained on the original IteraTeR dataset didn’t perform as well on the task-specific test sets.
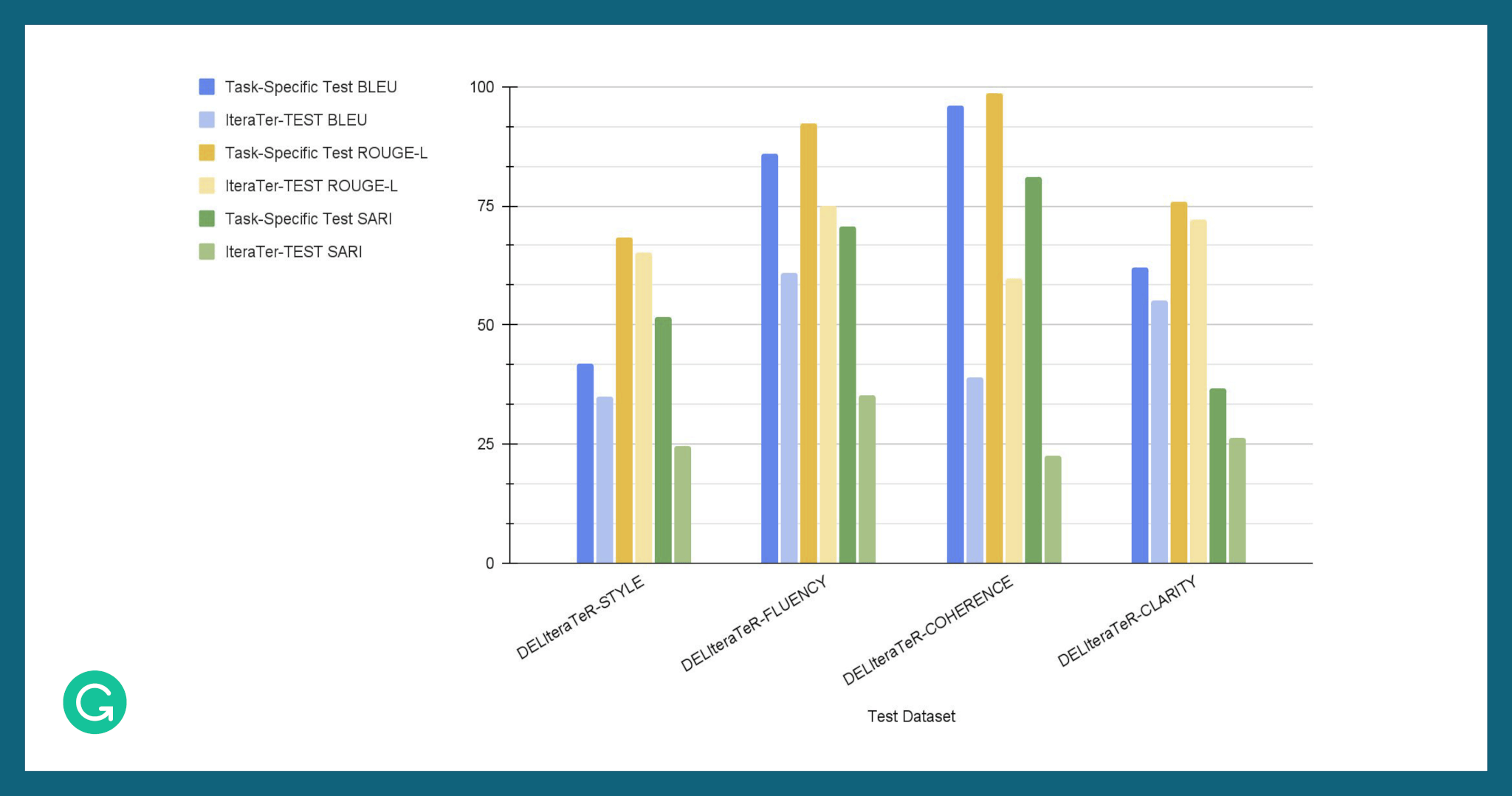
Models trained on task-specific data performed well on the corresponding task-specific test set. However, these models showed decreased performance against the full IteraTeR-TEST test set.
Edit Intent Trajectories
We also analyzed how edit intents change throughout the iterative revision process. We looked at how many instances of each possible edit intent transition (e.g., CLARITY -> FLUENCY) occurred at each level of depth.
When comparing writers of differing English proficiency, we found distinct patterns within the edit intent trajectories. Based on these differences in the flows of edit intents, we suspect there may be optimal paths for iterative editing, where the ordering and choices of the edit intents change the quality of the result. If so, this optimal path might be learned by a reinforcement learning algorithm. This is a direction we’d like to explore in future work. Please see the paper for more details on our analysis.
Looking forward
Effective systems for Iterative Text Revision could dramatically improve communication by scaling access to high-quality editing. Though the problem is challenging, we’re excited by the advances shown by DELIteraTeR and the IteraTeR+ dataset, including pushing the state-of-the-art of the Iterative Text Revision task as compared to the baseline of human editing.
With further improvements to the dataset and models, we believe the results of this approach can continue to improve. For instance, the augmented datasets were only available at the sentence level, so including more contextual information in the dataset could unlock the full potential of multisentence modeling.
Interested in working on problems like these? Grammarly’s NLP team is hiring! Check out our open roles for more information.
¹ For more information, see the research paper by Grammarly researchers Zae Myung Kim, Vipul Raheja, and Dhruv Kumar, along with collaborators Wanyu Du (University of Virginia) and Dongyeop Kang (University of Minnesota). This paper appeared at the 2022 Conference on Empirical Methods in Natural Language Processing. Zae Myung Kim, a PhD student at the University of Minnesota, contributed to this work as a research intern at Grammarly.